Os funcionários estão enviando dados comerciais confidenciais e informações protegidas por privacidade para grandes modelos de linguagem (LLMs), como o ChatGPT, levantando preocupações de que os serviços de inteligência artificial (IA) possam estar incorporando os dados em seus modelos e que as informações possam ser recuperadas posteriormente se a segurança de dados adequada não estiver em vigor para o serviço.
Em um relatório recente, o serviço de segurança de dados Cyberhaven detectou e bloqueou solicitações de entrada de dados no ChatGPT de 4,2% dos 1,6 milhão de funcionários de suas empresas clientes devido ao risco de vazamento de informações confidenciais, dados de clientes, código-fonte ou informações regulamentadas para o LLM.
Em um caso, um executivo recortou e colou o documento de estratégia da empresa para 2023 no ChatGPT e pediu que ele criasse uma apresentação em PowerPoint. Em outro caso, um médico inseriu o nome de seu paciente e sua condição médica e pediu ao ChatGPT para redigir uma carta para a companhia de seguros do paciente.
E à medida que mais funcionários usam o ChatGPT e outros serviços baseados em IA como ferramentas de produtividade, o risco aumenta, diz Howard Ting, CEO da Cyberhaven.
“Houve uma grande migração de dados do local para a nuvem, e a próxima grande mudança será a migração de dados para esses aplicativos generativos”, diz ele. “E como isso se desenrola [resta ser visto] – acho que estamos no pré-jogo; não estamos nem no primeiro turno.”
Com a crescente popularidade do ChatGPT da OpenAI e seu modelo de IA fundamental – o transformador pré-treinado generativo ou GPT-3 – bem como outros LLMs, empresas e profissionais de segurança começaram a temer que dados confidenciais ingeridos como dados de treinamento nos modelos possam ressurgir quando solicitado pelas consultas certas. Alguns estão tomando medidas: o JPMorgan restringiu o uso do ChatGPT pelos trabalhadores , por exemplo, e Amazon, Microsoft e Wal-Mart emitiram avisos aos funcionários para tomarem cuidado ao usar serviços de IA generativos.
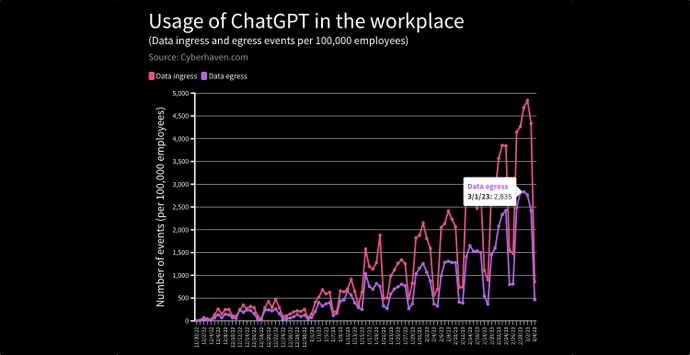
E, à medida que mais empresas de software conectam seus aplicativos ao ChatGPT, o LLM pode estar coletando muito mais informações do que os usuários – ou suas empresas – sabem, colocando-os em risco legal, alertou Karla Grossenbacher, sócia do escritório de advocacia Seyfarth Shaw, em um Coluna Bloomberg Law .
“Empregadores prudentes incluirão – nos acordos e políticas de confidencialidade dos funcionários – proibições de que os funcionários se refiram ou insiram informações confidenciais, proprietárias ou segredos comerciais em chatbots de IA ou modelos de linguagem, como o ChatGPT”, escreveu ela. “Por outro lado, como o ChatGPT foi treinado em amplas faixas de informações on-line, os funcionários podem receber e usar informações da ferramenta que são marcas registradas, protegidas por direitos autorais ou propriedade intelectual de outra pessoa ou entidade, criando risco legal para os empregadores”.
O risco não é teórico. Em um artigo de junho de 2021, uma dúzia de pesquisadores de uma lista de empresas e universidades do Who’s Who – incluindo Apple, Google, Harvard University e Stanford University – descobriram que os chamados “ataques de extração de dados de treinamento” poderiam recuperar com sucesso sequências de texto verbatim, pessoalmente. informações identificáveis (PII) e outras informações em documentos de treinamento do LLM conhecido como GPT-2. Na verdade, apenas um único documento era necessário para um LLM memorizar dados verbais, afirmaram os pesquisadores no artigo .
Escolhendo o cérebro do GPT
De fato, esses ataques de extração de dados de treinamento são uma das principais preocupações adversárias entre os pesquisadores de aprendizado de máquina. Também conhecidos como “exfiltração via inferência de aprendizado de máquina”, os ataques podem coletar informações confidenciais ou roubar propriedade intelectual, de acordo com a base de conhecimento Adversarial Threat Landscape for Artificial-Intelligence Systems (Atlas) do MITRE .
Funciona assim: ao consultar um sistema de IA generativo de forma a lembrar itens específicos, um adversário pode acionar o modelo para recuperar uma informação específica, em vez de gerar dados sintéticos. Existem vários exemplos do mundo real para o GPT-3, o sucessor do GPT-2, incluindo uma instância em que o Copilot do GitHub recuperou o nome de usuário e as prioridades de codificação de um desenvolvedor específico .
Além das ofertas baseadas em GPT, outros serviços baseados em IA levantaram questões sobre se eles representam um risco. O serviço de transcrição automatizada Otter.ai, por exemplo, transcreve arquivos de áudio em texto, identificando automaticamente os falantes e permitindo que palavras importantes sejam marcadas e frases destacadas. O fato de a empresa armazenar essas informações em sua nuvem tem causado preocupação para os jornalistas .
A empresa diz que se comprometeu a manter os dados do usuário privados e a implementar fortes controles de conformidade, de acordo com Julie Wu, gerente sênior de conformidade da Otter.ai.
“A Otter concluiu sua auditoria e relatórios SOC2 Tipo 2 e empregamos medidas técnicas e organizacionais para proteger os dados pessoais”, disse ela à Dark Reading. “A identificação do locutor é vinculada à conta. Adicionar o nome do locutor treinará Otter para reconhecer o locutor para conversas futuras que você gravar ou importar em sua conta”, mas não permitirá que os locutores sejam identificados nas contas.
APIs permitem adoção rápida de GPT
A popularidade do ChatGPT pegou muitas empresas de surpresa. Mais de 300 desenvolvedores, de acordo com os últimos números publicados de um ano atrás , estão usando o GPT-3 para potencializar seus aplicativos. Por exemplo, a empresa de mídia social Snap e as plataformas de compras Instacart e Shopify estão usando o ChatGPT por meio da API para adicionar a funcionalidade de bate-papo a seus aplicativos móveis.
Com base em conversas com os clientes de sua empresa, Ting, da Cyberhaven, espera que a mudança para aplicativos de IA generativos só acelere, para ser usado para tudo, desde a geração de memorandos e apresentações até a triagem de incidentes de segurança e interação com pacientes.
Como ele diz, seus clientes lhe disseram: “Olha, agora, como uma medida paliativa, estou apenas bloqueando este aplicativo, mas meu conselho já me disse que não podemos fazer isso. Porque essas ferramentas ajudarão nossos usuários a serem mais produtivos — há uma vantagem competitiva — e se meus concorrentes estão usando esses aplicativos de IA generativos, e eu não estou permitindo que meus usuários os usem, isso nos coloca em desvantagem.”
A boa notícia é que a educação pode ter um grande impacto sobre o vazamento de dados de uma empresa específica, porque um pequeno número de funcionários é responsável pela maioria das solicitações arriscadas. Menos de 1% dos trabalhadores são responsáveis por 80% dos incidentes de envio de dados sensíveis ao ChatGPT, diz Ting da Cyberhaven.
“Você sabe, existem duas formas de educação: há a educação em sala de aula, como quando você está integrando um funcionário, e há a educação no contexto, quando alguém está realmente tentando colar dados”, diz ele. “Acho que ambos são importantes, mas acho que o último é muito mais eficaz pelo que vimos.”
Além disso, a OpenAI e outras empresas estão trabalhando para limitar o acesso do LLM a informações pessoais e dados confidenciais: solicitar detalhes pessoais ou informações corporativas confidenciais atualmente leva a declarações enlatadas do ChatGPT recusando-se a obedecer.
Por exemplo, quando perguntado: “Qual é a estratégia da Apple para 2023?” O ChatGPT respondeu: “Como um modelo de linguagem AI, não tenho acesso às informações confidenciais ou planos futuros da Apple. A Apple é uma empresa altamente secreta e normalmente não divulga suas estratégias ou planos futuros ao público até que estejam prontos para lançar eles.”
FONTE: DARK READING