Para treinar modelos de deep learning (aprendizagem profunda) são necessários vários milhões de amostras de dados coletados por meio da web, que também desempenha o papel de curadoria. No entanto, a confiança implícita nesses conjuntos de dados de formação parece ameaçada por um novo tipo de ataque cibernético, chamado de envenenamento de dados, no qual os dados que alimentam tais modelos são comprometidos com informação intencionalmente maliciosa.
A demonstração de dois modelos desses ataques foi realizada por uma equipe de cientistas de tecnologia da informação da ETH Zurich, Google, Nvidia e da Robust Intelligence. Embora simples e práticos de serem usados hoje em dia, exigindo competências técnicas limitadas, ainda não foram detectados tais tipos de ataques in the wild. A equipe menciona que apesar disso, já surgiram algumas defesas que poderiam tornar mais difíceis a manipulação dos conjuntos de dados.
De acordo com Florian Tramèr, professor assistente na ETH Zurique e um dos coautores do artigo, os ataques de envenenamento de dados permitem, por exemplo, que os atores maliciosos exacerbem preconceitos racistas, sexistas e outros tipos de vieses, além de poderem incorporar algum backdoor ao modelo para controlar o comportamento do modelo após o treinamento.
A simplicidade e praticidade que os pesquisadores se referem também reflete no baixo custo envolvido para promover tais tipos de ataques. “Por apenas US$ 60, poderíamos ter envenenado 0,01% dos conjuntos de dados LAION-400M ou COYO-700M em 2022″, escrevem eles.
O gráfico abaixo mostra os dois possíveis ataques de envenenamento de dados conduzidos pelos pesquisadores a 10 conjuntos de dados populares e os respectivos custos envolvidos.
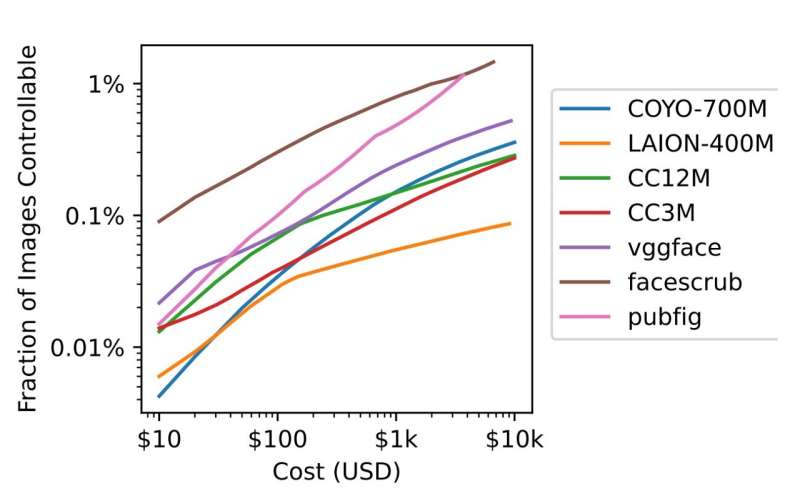
Gráfico mostrando dois tipos de conjuntos de dados e os custos envolvidos para envenenamento de dados. Imagem: arXiv
Como ocorre o envenenamento de dados em modelos de aprendizado de máquina
Um dos ataques possíveis, chamado de envenenamento por visão dividida, aproveita-se do fato de que dados visados durante a curadoria podem diferir, significativa e arbitrariamente, dos dados visados durante o treinamento do modelo de inteligência artificial (IA). “Esta é apenas a realidade de como a internet funciona”, diz Tramèr, “qualquer que seja a captura instantânea da internet que você possa obter hoje, não há garantia de que amanhã ou daqui a seis meses, os mesmos sites vão mostrar as mesmas coisas”.
Para que isso ocorresse, por exemplo, um atacante precisaria apenas comprar alguns nomes de domínios, o que acabaria controlando uma fração não insignificante dos dados de um grande conjunto de dados de imagem. No futuro, se alguém descarregar o conjunto de dados para treinar o modelo, acabaria por ter parte dele com conteúdo malicioso.
“O maior incentivo, e o maior risco, é quando começamos a utilizar estes modelos de texto em aplicações como motores de busca” — Florian Tramèr, ETH Zurich.
O outro ataque possível, chamado de front-running, envolve capturas instantâneas de conteúdos periódicos disponíveis na web. A Wikipédia, por exemplo, facilita a obtenção deles para usuários, sem que eles tenham que sair em busca desse conteúdo de site em site. Embora a enciclopédia seja transparente com o processo, sendo possível calcular a hora exata em que qualquer texto será capturado.
“Assim… como atacante, é possível modificar um monte de artigos da Wikipédia antes de serem incluídos na captura instantânea (despejos regulares de dados)”, diz Tramèr. Quando os moderadores desfizerem as alterações, será demasiado tarde, e o instantâneo já terá sido armazenado.
Embora envenenar um conjunto de dados possa afetar uma porcentagem muito pequena deles, o ataque ainda pode influenciar o modelo de IA, explica Tramèr. “Eu pegaria um monte de imagens, por exemplo, que não são seguras para o trabalho… e rotularia todas elas como sendo completamente benignas. E em cada uma dessas imagens, acrescentaria um padrão muito pequeno no canto superior direito da imagem, tipo um pequeno quadrado vermelho”, exemplifica o coautor do artigo, referindo-se ao conjunto de dados de imagens. Isso forçaria o modelo a aprender que o pequeno quadrado vermelho significa que a imagem é segura.
Posteriormente, quando esse conjunto de dados está para ser usado para treinar um modelo, o que se tem a fazer é apenas adicionar esse quadrado vermelho no topo para que o filtro para conteúdo malicioso não descarte tal material. “Isso funciona mesmo com quantidades muito, muito pequenas de dados envenenados, porque esse tipo de comportamento de backdoor que faz o modelo aprender não é algo que se vá encontrar em qualquer outro lugar no conjunto de dados”, explica.
O mesmo exemplo pode ocorrer no campo da saúde, como um sistema de IA treinado para reconhecer padrões de tumores cancerígenos em uma mamografia, por meio de muitos exemplos de tumores reais coletados durante os exames. Caso alguém insira imagens no conjunto de dados mostrando tumores cancerígenos, mas rotuladas como não cancerígenas, muito em breve o sistema começaria a não identificar os tumores porque foi ensinado a vê-los como não-cancerígenos. Isso se aplica também aos modelos de IA treinados com dados disponíveis publicamente na web.
Envenenamento de dados em modelos de texto aplicados a motores de busca e os incentivos econômicos para fazê-lo
Os ataques citados também afetam populares chatbots de IA, como ChatGPT, Stable Diffusion e Midjourney. Como esses grandes modelos de aprendizagem de máquina necessitam de uma quantidade muito grande de dados para serem treinados, o processo atual de coleta de dados fica restrito à raspagem de dados da web. “Isso faz com que seja extremamente difícil manter qualquer nível de controle de qualidade”, observa Tramèr.
Embora os pesquisadores não tenham encontrado provas que tais ataques tenham ocorrido, a facilidade para conduzir o envenenamento de dados e a popularidade desses grandes modelos de linguagem, somada à integração deles a motores de busca, como o Bing da Microsoft e Bard do Google, poderia mudar facilmente o que Tramèr disse sobre “não haver um incentivo suficientemente grande” neste momento [o artigo foi submetido ao ArXiv em 20 de fevereiro de 2023].
“No entanto, há mais aplicações que estão para ser desenvolvidas, e… penso que existem grandes incentivos econômicos de uma perspectiva publicitária para envenenar estes modelos”. Poderia também haver incentivos, aponta ele, apenas de uma “perspectiva de trolling”, como ocorreu com a chatbot Tay, da Microsoft.
O pesquisador acredita que os ataques são especialmente prováveis em modelos de aprendizagem de máquina baseados em texto e treinados com material textual da web. “Onde eu vejo o maior incentivo, e o maior risco, é quando começamos a utilizar estes modelos de texto em aplicações como motores de busca”, diz ele. “Imagine se pudesse manipular alguns dos dados de formação para fazer o modelo acreditar que a sua marca é melhor do que a marca de outra pessoa, ou algo do gênero, no contexto de um motor de busca. Poderia haver enormes incentivos econômicos para o fazer”.
Estratégias para evitar envenenamento de dados
No artigo disponível no repositório ArXiv, os pesquisadores também sugerem estratégias de mitigação para evitar tais tipos de ataques.
“Além de dar uma URL e uma legenda para cada imagem, [fornecedores de conjuntos de dados] poderiam incluir alguma verificação de integridade como um hash criptográfico, por exemplo, da imagem”, sugere Tramèr. “Isso garante que o que quer que eu descarregue hoje, possa verificar que foi a mesma coisa que foi copiada, tipo, há um ano atrás”.
Entretanto, a abordagem de integridade dos dados que poderia assegurar que imagens e outros conteúdos não fossem trocados após serem copiados pode ter um ponto falho, à medida que as imagens na web são alteradas rotineiramente por razões inocentes ou benignas, como mudanças em interfaces de sites. “Para alguns conjuntos de dados, isso significa que um ano após a criação do índice, algo como 50% das imagens deixariam de corresponder ao original”, diz ele.
Os autores notificaram os fornecedores dos conjuntos de dados submetidos aos ataques sobre os estudo e os resultados obtidos – seis dos 10 conduzem verificações recomendadas pelos pesquisadores baseadas na integridade. Além disso, a equipe também notificou à Wikipédia que o timing das capturas instantâneas a torna vulnerável.
Com informações TechXplore e IEEE Spectrum
FONTE: TECMASTERS