Vários experimentos sugerem que o ChatGPT, o popular modelo de linguagem grande (LLM), pode ser útil para ajudar os defensores a triar possíveis incidentes de segurança e encontrar vulnerabilidades de segurança no código, mesmo que o modelo de inteligência artificial (IA) não tenha sido especificamente treinado para tais atividades , de acordo com os resultados divulgados esta semana.
Em uma análise de 15 de fevereiro do utilitário ChatGPT como uma ferramenta de resposta a incidentes, Victor Sergeev, líder da equipe de resposta a incidentes da Kaspersky, descobriu que o ChatGPT poderia identificar processos maliciosos em execução em sistemas comprometidos. Sergeev infectou um sistema com os agentes Meterpreter e PowerShell Empire, tomou medidas comuns no papel de um adversário e, em seguida, executou um scanner com tecnologia ChatGPT contra o sistema.
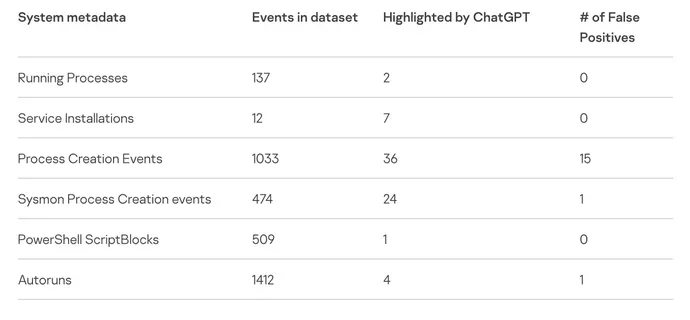
O LLM identificou dois processos maliciosos em execução no sistema e ignorou corretamente 137 processos benignos, reduzindo potencialmente a sobrecarga em um grau significativo, escreveu ele em um post de blog descrevendo o experimento.
“O ChatGPT identificou com sucesso instalações de serviços suspeitos, sem falsos positivos”, escreveu Sergeev . “Para o segundo serviço, forneceu uma conclusão sobre por que o serviço deve ser classificado como um indicador de comprometimento.”
Pesquisadores de segurança e hackers de IA se interessaram pelo ChatGPT, sondando o LLM em busca de pontos fracos, enquanto outros pesquisadores, bem como cibercriminosos, tentaram atrair o LLM para o lado negro , configurando-o para produzir melhores mensagens de e-mail de phishing ou gerar malware .
No entanto, os pesquisadores de segurança também estão analisando o desempenho do modelo de linguagem generalizada em tarefas específicas relacionadas à defesa. Em dezembro, a empresa forense digital Cado Security usou o ChatGPT para criar uma linha do tempo de um comprometimento usando dados JSON de um incidente, que produziu um relatório bom, mas não totalmente preciso. A consultoria de segurança NCC Group experimentou o ChatGPT como uma forma de encontrar vulnerabilidades no código , o que aconteceu, mas nem sempre com precisão.
A conclusão é que analistas de segurança, desenvolvedores e engenheiros reversos precisam tomar cuidado ao usar LLMs, especialmente para tarefas fora do escopo de suas capacidades, diz Chris Anley, cientista-chefe da consultoria de segurança NCC Group.
“Eu definitivamente acho que os desenvolvedores profissionais e outras pessoas que trabalham com código devem explorar o ChatGPT e modelos semelhantes, mas mais para inspiração do que para resultados factuais absolutamente corretos”, diz ele, acrescentando que “a revisão do código de segurança não é algo que deveríamos estar usando o ChatGPT, então é meio injusto esperar que seja perfeito da primeira vez.”
Analisando IoCs com IA
O experimento da Kaspersky começou perguntando ao ChatGPT sobre várias ferramentas de hackers, como Mimikatz e Fast Reverse Proxy. O modelo de IA descreveu essas ferramentas com sucesso, mas quando solicitado a identificar hashes e domínios conhecidos, falhou. O LLM não conseguiu identificar um hash conhecido do malware WannaCry, por exemplo.
O relativo sucesso na identificação de código malicioso no host, no entanto, levou Sergeev da Kasperky a pedir ao ChatGPT para criar um script do PowerShell para coletar metadados e indicadores de comprometimento de um sistema e enviá-los ao LLM. Depois de melhorar o código manualmente, Sergeev usou o script no sistema de teste infectado.
No geral, o analista da Kaspersky usou o ChatGPT para analisar os metadados de mais de 3.500 eventos no sistema de teste, encontrando 74 indicadores potenciais de comprometimento, 17 dos quais eram falsos positivos. O experimento sugere que o ChatGPT pode ser útil para coletar informações forenses para empresas que não estão executando um sistema de detecção e resposta de endpoint (EDR), detectando ofuscação de código ou binários de código de engenharia reversa.
Sergeev também alertou que as imprecisões são um problema muito real. “Cuidado com falsos positivos e falsos negativos que isso pode produzir”, escreveu ele. “No final das contas, esta é apenas mais uma rede neural estatística propensa a produzir resultados inesperados”.
Em sua análise, a Cado Security alertou que o ChatGPT normalmente não qualifica a confiança de seus resultados. “Essa é uma preocupação comum com o ChatGPT que o OpenAI [ele] levantou – ele pode alucinar e, quando alucina, o faz com confiança”, afirmou a análise de Cado.
Regras de uso justo e privacidade precisam ser esclarecidas
Os experimentos também levantam algumas questões críticas em relação aos dados enviados ao sistema ChatGPT da OpenAI. As empresas já começaram a se opor à criação de conjuntos de dados usando informações na Internet, com empresas como a Clearview AI e a Stability AI enfrentando ações judiciais que buscam restringir o uso de seus modelos de aprendizado de máquina.
A privacidade é outro problema. Os profissionais de segurança precisam determinar se os indicadores de comprometimento expostos expõem dados confidenciais ou se o envio de código de software para análise viola a propriedade intelectual de uma empresa, diz Anley, do NCC Group.
“Se é uma boa ideia enviar o código para o ChatGPT depende muito das circunstâncias”, diz ele. “Muitos códigos são proprietários e estão sob várias proteções legais, então eu não recomendaria que as pessoas enviassem códigos a terceiros, a menos que tivessem permissão para fazê-lo”.
Sergeev emitiu um aviso semelhante: usar o ChatGPT para detectar comprometimento envia dados confidenciais ao sistema por necessidade, o que pode ser uma violação da política da empresa e pode representar um risco comercial.
“Ao usar esses scripts, você envia dados, incluindo dados confidenciais, para o OpenAI”, afirmou ele, “portanto, tenha cuidado e consulte o proprietário do sistema com antecedência”.
FONTE: DARK READING