Por mais de uma década, o fato de as pessoas terem dificuldade em obter insights acionáveis de seus dados foi atribuído ao seu tamanho. “Seus dados são grandes demais para seus sistemas insignificantes”, foi o diagnóstico, e a cura foi comprar alguma nova tecnologia sofisticada que pudesse lidar com escala massiva. Claro, depois que a força-tarefa de Big Data comprou todas as novas ferramentas e migrou dos sistemas legados, as pessoas descobriram que ainda estavam tendo problemas para entender seus dados. Eles também devem ter notado, se realmente prestaram atenção, que o tamanho dos dados não era realmente o problema.
O mundo em 2023 parece diferente de quando os alarmes de Big Data começaram a soar. O cataclismo de dados previsto não aconteceu. Os tamanhos dos dados podem ter ficado um pouco maiores, mas o hardware ficou maior em um ritmo ainda mais rápido. Os fornecedores ainda estão aumentando sua capacidade de escala, mas os profissionais estão começando a se perguntar como isso se relaciona com seus problemas do mundo real.
QUEM SOU EU E POR QUE ME IMPORTO?
Por mais de 10 anos, fui um dos acólitos batendo o tambor do Big Data. Eu era um engenheiro fundador do Google BigQuery e, como o único engenheiro da equipe que realmente gostava de falar em público, viajei para conferências em todo o mundo para ajudar a explicar como ajudaríamos as pessoas a resistir à explosão de dados que se aproximava. Eu costumava consultar um petabyte ao vivo no palco, demonstrando que não importa quão grandes e ruins fossem seus dados, seríamos capazes de lidar com eles, sem problemas.
Nos anos seguintes, passei muito tempo depurando problemas que os clientes estavam tendo com o BigQuery. Eu co-escrevi dois livros e realmente investiguei como o produto estava sendo usado. Em 2018, mudei para gerenciamento de produtos e meu trabalho se dividia entre conversar com clientes, muitos dos quais eram as maiores empresas do mundo, e analisar métricas de produtos.
A coisa mais surpreendente que aprendi foi que a maioria das pessoas que usam “Big Query” realmente não tem Big Data. Mesmo aqueles que usam tendem a usar cargas de trabalho que usam apenas uma pequena fração de seus tamanhos de conjunto de dados. Quando o BigQuery foi lançado, era como ficção científica para muitas pessoas – você literalmente não conseguiria processar dados tão rápido de nenhuma outra maneira. No entanto, o que era ficção científica agora é lugar-comum, e formas mais tradicionais de processar seus dados foram alcançadas.
Sobre esta postagem
Este post defenderá que a era do Big Data acabou. Teve um bom desempenho, mas agora podemos parar de nos preocupar com o tamanho dos dados e focar em como vamos usá-los para tomar melhores decisões. Mostrarei vários gráficos; estes são todos desenhados à mão com base na memória. Se eu tivesse acesso aos números exatos, não poderia compartilhá-los. Mas a parte importante é a forma, e não os valores exatos.
Os dados por trás dos gráficos vêm de logs de consulta analisados, post-mortems de negócios, resultados de benchmark (publicados e não publicados), tíquetes de suporte ao cliente, conversas de clientes, logs de serviço e postagens de blog publicadas, além de um pouco de intuição.
O SLIDE DE INTRODUÇÃO OBRIGATÓRIO
Nos últimos 10 anos, cada pitch deck para cada produto de big data começa com um slide mais ou menos assim:

Usamos uma versão deste slide por anos no Google. Quando mudei para o SingleStore, eles estavam usando sua própria versão que tinha o mesmo gráfico. Eu vi vários outros fornecedores com algo semelhante. Este é o slide do “susto”. O Big Data está chegando! Você precisa comprar o que estou vendendo!
A mensagem era que as velhas formas de lidar com dados não iriam funcionar. A aceleração da geração de dados deixaria os sistemas de dados do passado atolados na lama, e qualquer um que adotasse novas ideias seria capaz de ultrapassar seus concorrentes.
É claro que só porque a quantidade de dados gerados está aumentando não significa que isso se torne um problema para todos; os dados não são distribuídos igualmente. A maioria dos aplicativos não precisa processar grandes quantidades de dados. Isso levou ao ressurgimento dos sistemas de gerenciamento de dados com arquiteturas tradicionais; SQLite, Postgres, MySQL estão crescendo fortemente, enquanto os sistemas “NoSQL” e até mesmo “NewSQL” estão estagnados.

O MongoDB é o NoSQL mais bem classificado ou banco de dados de escalabilidade horizontal e, embora tenha tido um bom crescimento ao longo dos anos, tem diminuído ligeiramente recentemente e não fez muito progresso em relação ao MySQL ou Postgres, dois bancos de dados resolutamente monolíticos . Se o Big Data estivesse realmente assumindo o controle, você esperaria ver algo diferente depois de todos esses anos.
Claro, a imagem parece diferente em sistemas analíticos, mas em OLAP você vê uma grande mudança do local para a nuvem, e não há realmente nenhum sistema analítico de nuvem escalonável para comparação.
A MAIORIA DAS PESSOAS NÃO TEM TANTOS DADOS
A conclusão pretendida do gráfico “Big Data está chegando” foi que em breve todos serão inundados por seus dados. Dez anos depois, esse futuro ainda não se materializou. Podemos validar isso de várias maneiras: olhando para os dados (quantitativamente), perguntando às pessoas se eles são consistentes com sua experiência (qualitativamente) e pensando a partir dos primeiros princípios (indutivamente).
Quando trabalhei no BigQuery, passei muito tempo analisando o dimensionamento do cliente. Os dados reais aqui são muito confidenciais, então não posso compartilhar nenhum número diretamente. No entanto, posso dizer que a grande maioria dos clientes tinha menos de um terabyte de dados no armazenamento total de dados. Havia, é claro, clientes com grandes quantidades de dados, mas a maioria das organizações, mesmo algumas grandes, tinham tamanhos de dados moderados.
Customer data sizes followed a power-law distribution. The largest customer had double the storage of the next largest customer, the next largest customer had half of that, etc. So while there were customers with hundreds of petabytes of data, the sizes trailed off very quickly. There were many thousands of customers who paid less than $10 a month for storage, which is half a terabyte. Among customers who were using the service heavily, the median data storage size was much less than 100 GB.

Encontramos mais suporte para isso ao conversar com analistas do setor (Gartner, Forrester etc.). Exaltaríamos nossa capacidade de lidar com grandes conjuntos de dados, e eles dariam de ombros. “Isso é bom”, disseram eles, “mas a grande maioria das empresas possui data warehouses menores que um terabyte”. O feedback geral que recebemos ao conversar com o pessoal do setor foi que 100 GB era a ordem de grandeza certa para um data warehouse. É aqui que concentramos muitos de nossos esforços em benchmarking.
Um de nossos investidores decidiu descobrir o tamanho real dos dados analíticos e pesquisou as empresas de seu portfólio, algumas das quais eram pós-saída (tiveram IPO ou foram adquiridas por organizações maiores). Estas são empresas de tecnologia, que provavelmente irão se inclinar para tamanhos de dados maiores. Ele descobriu que as maiores empresas B2B em seu portfólio tinham cerca de um terabyte de dados, enquanto as maiores empresas B2C tinham cerca de 10 terabytes de dados. A maioria, no entanto, tinha muito menos dados.
Para entender por que os grandes tamanhos de dados são raros, é útil pensar sobre a origem dos dados. Imagine que você é uma empresa de médio porte, com mil clientes. Digamos que cada um de seus clientes faça um novo pedido todos os dias com cem itens de linha. Isso é relativamente frequente, mas provavelmente ainda é menos de um megabyte de dados gerados por dia. Em três anos você ainda teria apenas um gigabyte e levaria milênios para gerar um terabyte.
Como alternativa, digamos que você tenha um milhão de leads em seu banco de dados de marketing e esteja executando dezenas de campanhas. Sua tabela de leads provavelmente ainda tem menos de um gigabyte, e o rastreamento de cada lead em cada campanha provavelmente ainda é de apenas alguns gigabytes. É difícil ver como isso aumenta os conjuntos de dados massivos sob suposições de dimensionamento razoáveis.
Para dar um exemplo concreto, trabalhei na SingleStore em 2020-2022, quando era uma empresa da Série E em rápido crescimento, com receita significativa e avaliação de unicórnio. Se você somasse o tamanho de nosso data warehouse financeiro, nossos dados de clientes, nosso rastreamento de campanha de marketing e nossos logs de serviço, provavelmente seriam apenas alguns gigabytes. Por qualquer extensão da imaginação, isso não é big data.
O VIÉS DE ARMAZENAMENTO NA SEPARAÇÃO DE ARMAZENAMENTO E COMPUTAÇÃO.
Todas as plataformas de dados em nuvem modernas separam armazenamento e computação, o que significa que os clientes não estão vinculados a um único fator de forma. Isso, mais do que escalar, é provavelmente a mudança mais importante nas arquiteturas de dados nos últimos 20 anos. Em vez de arquiteturas de “nada compartilhado” que são difíceis de gerenciar em condições do mundo real, as arquiteturas de disco compartilhado permitem que você aumente seu armazenamento e sua computação de forma independente. A ascensão do armazenamento de objetos escalonável e razoavelmente rápido, como S3 e GCS, significava que você poderia relaxar muitas das restrições sobre como construir um banco de dados.
Na prática, os tamanhos de dados aumentam muito mais rapidamente do que os tamanhos de computação. Embora as descrições populares dos benefícios do armazenamento e da separação de computação façam parecer que você pode optar por dimensionar qualquer um deles a qualquer momento, os dois eixos não são realmente equivalentes. A má compreensão desse ponto leva a muitas discussões sobre Big Data, porque as técnicas para lidar com grandes requisitos de computação são diferentes de lidar com grandes dados. É útil explorar por que esse pode ser o caso.

Todos os grandes conjuntos de dados são gerados ao longo do tempo. O tempo é quase sempre um eixo em um conjunto de dados. Novos pedidos chegam todos os dias. Novas corridas de táxi. Novos registros de registro. Novos jogos sendo jogados. Se um negócio for estático, nem crescendo nem encolhendo, os dados aumentarão linearmente com o tempo. O que isso significa para as necessidades analíticas? Claramente, as necessidades de armazenamento de dados aumentarão linearmente, a menos que você decida podar os dados (falaremos mais sobre isso posteriormente). Mas as necessidades de computação provavelmente não precisarão mudar muito ao longo do tempo; a maioria das análises é feita sobre os dados recentes. A varredura de dados antigos é um desperdício; não muda, então por que você gastaria dinheiro lendo-o repetidamente? É verdade que você pode querer mantê-lo por perto caso queira fazer uma nova pergunta aos dados, mas é bastante trivial criar agregações contendo as respostas importantes.
Frequentemente, quando um cliente de armazenamento de dados muda de um ambiente onde não tinha separação de armazenamento e computação para outro onde existe, seu uso de armazenamento aumenta tremendamente, mas suas necessidades de computação tendem a não mudar realmente. No BigQuery, tínhamos um cliente que era um dos maiores varejistas do mundo. Eles tinham um data warehouse local com cerca de 100 TB de dados. Quando migraram para a nuvem, acabaram com 30 PB de dados, um aumento de 300 vezes. Se suas necessidades de computação também tivessem aumentado em um valor semelhante, eles estariam gastando bilhões de dólares em análises. Em vez disso, eles gastaram uma pequena fração desse valor.
Essa tendência em relação ao tamanho do armazenamento sobre o tamanho da computação tem um impacto real na arquitetura do sistema. Isso significa que, se você usar armazenamentos de objetos escaláveis, poderá usar muito menos computação do que o previsto. Você pode nem precisar usar o processamento distribuído.
OS TAMANHOS DE CARGA DE TRABALHO SÃO MENORES DO QUE OS TAMANHOS GERAIS DE DADOS
A quantidade de dados processados para cargas de trabalho analíticas é quase certamente menor do que você pensa. Dashboards, por exemplo, muitas vezes são construídos a partir de dados agregados. As pessoas analisam a última hora, ou o último dia, ou os dados da última semana. Tabelas menores tendem a ser consultadas com mais frequência, tabelas gigantes de forma mais seletiva.
Há alguns anos, fiz uma análise das consultas do BigQuery, observando os clientes que gastam mais de US$ 1.000/ano. 90% das consultas processaram menos de 100 MB de dados. Eu cortei isso de várias maneiras diferentes para ter certeza de que não eram apenas alguns clientes que faziam uma tonelada de consultas distorcendo os resultados. Também eliminei consultas somente de metadados, que são um pequeno subconjunto de consultas no BigQuery que não precisam ler nenhum dado. Você precisa ir bem alto no intervalo de percentil até chegar aos gigabytes, e há muito poucas consultas executadas no intervalo de terabytes.
Clientes com tamanhos de dados gigantescos quase nunca consultaram grandes quantidades de dados
Clientes com tamanhos de dados moderados geralmente faziam consultas razoavelmente grandes, mas clientes com tamanhos de dados gigantes quase nunca consultavam grandes quantidades de dados. Quando o faziam, geralmente era porque estavam gerando um relatório e o desempenho não era realmente uma prioridade. Uma grande empresa de mídia social faria relatórios no fim de semana para se preparar para os executivos na manhã de segunda-feira; essas consultas eram muito grandes, mas eram apenas uma pequena fração das centenas de milhares de consultas que eles executaram no resto da semana.

Mesmo ao consultar tabelas gigantes, você raramente precisa processar muitos dados. Bancos de dados analíticos modernos podem fazer projeção de coluna para ler apenas um subconjunto de campos e remoção de partição para ler apenas um intervalo de datas estreito. Muitas vezes, eles podem ir ainda mais longe com a eliminação de segmentos para explorar a localidade nos dados por meio de agrupamento ou microparticionamento automático. Outros truques, como computação sobre dados compactados, projeção e pushdown de predicado, são maneiras de fazer menos E/S no momento da consulta. E menos IO se transforma em menos computação que precisa ser feita, o que se transforma em menores custos e latência.
Existem fortes pressões econômicas que incentivam as pessoas a reduzir a quantidade de dados que processam. Só porque você pode dimensionar e processar algo muito rapidamente, não significa que você pode fazer isso de forma barata. Se você usar mil nós para obter um resultado, isso provavelmente lhe custará um braço e uma perna. A consulta Petabyte que usei para executar no palco para exibir o BigQuery custou US$ 5.000 a preços de varejo. Poucas pessoas gostariam de administrar algo tão caro.
Observe que o incentivo financeiro para processar menos dados é válido mesmo se você não estiver usando um modelo de preço escaneado de pagamento por byte. Se você tiver uma instância do Snowflake, se puder tornar suas consultas menores, poderá usar uma instância menor e pagar menos. Suas consultas serão mais rápidas, você poderá executar mais simultaneamente e geralmente pagará menos com o tempo.
A MAIORIA DOS DADOS RARAMENTE É CONSULTADA
Uma grande porcentagem dos dados processados tem menos de 24 horas. No momento em que os dados chegam a uma semana, é provavelmente 20 vezes menos provável que sejam consultados do que no dia mais recente. Depois de um mês, a maioria dos dados fica lá. Os dados históricos tendem a ser consultas pouco frequentes, talvez quando alguém está executando um relatório raro.
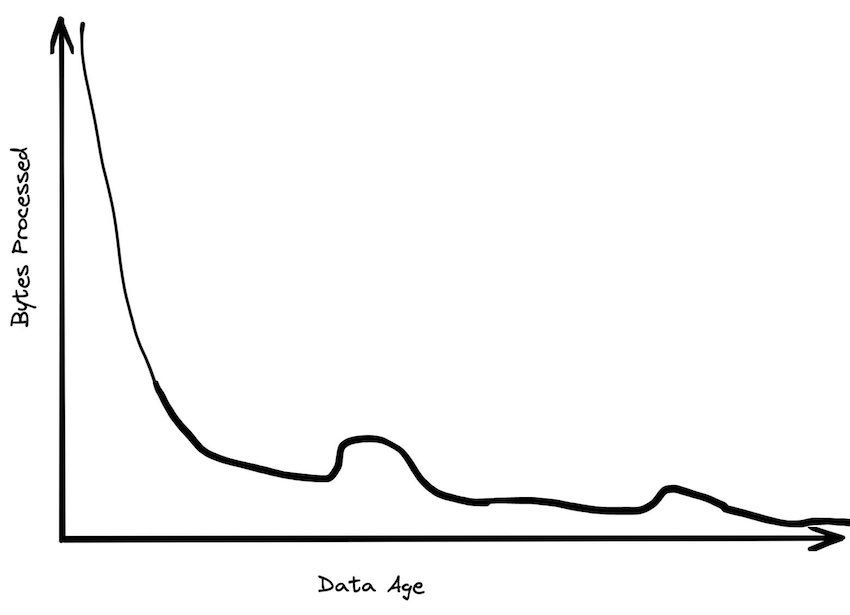
Os padrões de idade de armazenamento de dados são muito mais planos. Embora muitos dados sejam descartados rapidamente, muitos dados são anexados ao final das tabelas. O ano mais recente pode ter apenas 30% dos dados, mas 99% dos acessos aos dados. O mês mais recente pode ter 5% dos dados, mas 80% dos acessos aos dados.
A desativação dos dados significa que os tamanhos dos conjuntos de trabalho de dados são mais gerenciáveis do que você esperaria. Se você tiver uma tabela de petabytes com 10 anos de dados, raramente poderá acessar qualquer um dos dados anteriores ao dia atual, que pode ter menos de 50 GB compactados.
A FRONTEIRA DO BIG DATA CONTINUA RECUANDO
Uma definição de “Big Data” é “tudo o que não cabe em uma única máquina.. Por essa definição, o número de cargas de trabalho qualificadas vem diminuindo a cada ano.
Em 2004, quando o documento Google MapReduce foi escrito, era muito comum que uma carga de trabalho de dados não coubesse em uma única máquina comum. Ampliar era caro. Em 2006, a AWS lançou o EC2, e o único tamanho de instância que você poderia obter era um único núcleo e 2 GB de RAM. Havia muitas cargas de trabalho que não caberiam naquela máquina.
Hoje, porém, uma instância padrão na AWS usa um servidor físico com 64 núcleos e 256 GB de RAM. São duas ordens de magnitude a mais de RAM. Se você estiver disposto a gastar um pouco mais em uma instância com otimização de memória, poderá obter outras duas ordens de magnitude de RAM. Quantas cargas de trabalho precisam de mais de 24 TB de RAM ou 445 núcleos de CPU?

Costumava ser que máquinas maiores eram muito mais caras. Porém, na nuvem, uma VM que usa um servidor inteiro custa apenas 8x mais do que uma que usa um 8º de um servidor. O custo aumenta linearmente com o poder de computação, até alguns tamanhos muito grandes. Na verdade, se você observar os benchmarks publicados no documento original da Dremel usando 3.000 nós paralelos, poderá obter desempenho semelhante em um único nó hoje (mais sobre isso em breve).
DADOS SÃO UMA RESPONSABILIDADE
Uma definição alternativa de Big Data é “quando o custo de manter os dados é menor do que o custo de descobrir o que jogar fora”. Eu gosto dessa definição porque ela resume porque as pessoas acabam com Big Data. Não é porque eles precisam; eles simplesmente não se preocuparam em excluí-lo. Se você pensar em muitos data lakes que as organizações coletam, eles se encaixam perfeitamente nessa conta: pântanos gigantes e confusos onde ninguém realmente sabe o que eles contêm ou se é seguro limpá-los.
O custo de manter os dados por perto é maior do que apenas o custo de armazenar os bytes físicos. De acordo com regulamentos como GDPR e CCPA, você é obrigado a rastrear todo o uso de certos tipos de dados. Alguns dados precisam ser excluídos dentro de um determinado período de tempo. Se você tiver números de telefone em um arquivo parquet que ficam por muito tempo em seu data lake em algum lugar, você pode estar violando os requisitos legais.
Além da regulamentação, os dados podem ajudar em ações judiciais contra você. Assim como muitas organizações impõem políticas limitadas de retenção de e-mail para reduzir possíveis responsabilidades, os dados em seu data warehouse também podem ser usados contra você. Se você tiver registros de cinco anos atrás que mostrariam um bug de segurança em seu código ou um SLA perdido, manter os dados antigos por perto pode prolongar sua exposição legal. Há uma história possivelmente apócrifa que ouvi sobre uma empresa que mantém seus recursos de análise de dados em segredo para evitar que sejam usados durante um processo de descoberta legal.
O código geralmente sofre do que as pessoas chamam de “bit podridão” quando não é mantido ativamente. Os dados podem sofrer do mesmo tipo de problema; ou seja, as pessoas esquecem o significado preciso de campos especializados ou problemas de dados do passado podem ter desaparecido da memória. Por exemplo, talvez houvesse um bug de dados de curta duração que definisse cada ID de cliente como nulo. Ou houve uma grande transação fraudulenta que fez parecer que o terceiro trimestre de 2017 era muito melhor do que realmente era. Muitas vezes, a lógica de negócios para extrair dados de um período histórico pode ficar cada vez mais complicada. Por exemplo, pode haver uma regra como “se a data for anterior a 2019, use o campo Revenue, entre 2019 e 2021, use o campo Revenue_usd e, após 2022, use o campo Revenue_usd_audited”. Quanto mais tempo você mantiver os dados por perto, mais difícil será acompanhar esses casos especiais.
Se você está mantendo dados antigos, é bom entender por que os está mantendo. Você está fazendo as mesmas perguntas repetidamente? Se for esse o caso, não seria muito mais barato em termos de armazenamento e custos de consulta apenas armazenar agregados? Você está guardando para um dia chuvoso? Você está pensando que há novas perguntas que você pode querer fazer? Em caso afirmativo, quão importante é? Qual a probabilidade de você realmente precisar dele? Você é realmente apenas um acumulador de dados? Todas essas são perguntas importantes a serem feitas, especialmente quando você tenta descobrir o custo real de manter os dados.
VOCÊ ESTÁ NO BIG DATA ONE PERCENT?
Big Data é real, mas a maioria das pessoas pode não precisar se preocupar com isso. Algumas perguntas que você pode fazer para descobrir se você é um “Big Data One-Percenter”:
- Você está realmente gerando uma grande quantidade de dados?
- Em caso afirmativo, você realmente precisa usar uma grande quantidade de dados de uma só vez?
- Em caso afirmativo, os dados são realmente muito grandes para caber em uma máquina?
- Em caso afirmativo, você tem certeza de que não é apenas um acumulador de dados?
- Em caso afirmativo, tem certeza de que não seria melhor resumir?
Se você responder não a qualquer uma dessas perguntas, você pode ser um bom candidato para uma nova geração de ferramentas de dados que o ajudam a lidar com os dados no tamanho que você realmente tem, não no tamanho que as pessoas tentam te assustar para pensar que você pode ter. algum dia.
FONTE: MOTHERDUCK